简单分页
ES中执行一个简单’浅’分页, 每页5条数据, 取前三页
1 |
|
ES的查询阶段
我们假设查询的index只有primary shards, 没有 replica shards, ES查询分为query-fetch两个阶段, query阶段做查询规划, fetch阶段具体的从各shards取数据
(图片来自网络, 如有侵权请联系删除)
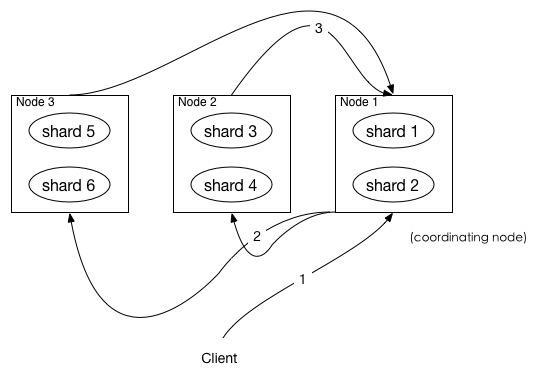
- client发起一次查询, node1接收到请求并创建一个from+size大小的优先队列用于后续保存结果.
- 将请求广播到涉及到的 shards,每个 shard 在内部执行搜索请求,然后,将结果存到内部的大小同样为 from + size 的优先级队列
- 每个shard把自身优先队列数据返回给coordination node, 做一次合并排序后存到自身的优先队列中, 这里队列中的数据只是一个标识, 并不是实际的数据
(图片来自网络, 如有侵权请联系删除)
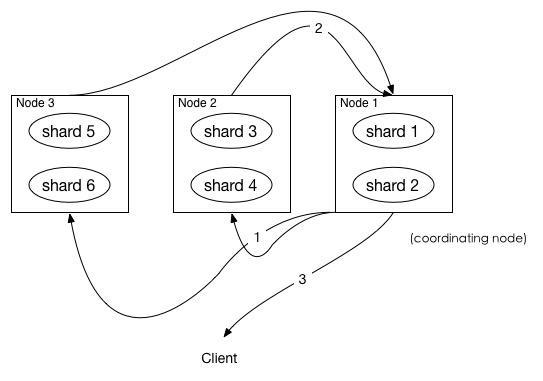
- coordinating node 发送 GET 请求到相关shards, 这里只发送需要返回给client的size条数据的请求来取信息详情
- shard 根据 doc 的 _id 取到数据详情,然后返回给 coordinating node
- coordinating node 返回数据给 Client
需要取的数据可能在不同分片, 也可能在同一分片, coordinating node 使用 multi-get来避免多次去同一分片取数据, 从而提高性能.
什么是深分页?
假设我们在一个数据集上利用上述方式查询第1001页的数据, 每页10条数据, 数据集共10个分片,那么ES每个分片会排序自己前10010条数据, 协调节点取回每个分片上排序好的10010条数据, 这时主节点共接收10010 * 10 = 100100条数据, 对这些数据排序后取出前10010条数据, 最后再返回10000->10010这10条数据. 我们可以看到这个过程有巨大的IO, CPU, 内存开销, 而且上述只是一个查询请求所产生的开销, 如果成千上万的并发请求执行, 后果可想而知. ES对这种情况进行了保护, 如果强行进行此类查询,会返回如下错误:
1 | query_phase_execution_exception: Result window is too large, from + size must be less than or equal to: [10000] but was [47100]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting. |
错误提示描述很清晰, 我们可以通过改变index.max_result_window参数来设置保护的result window大小, 如果机器配置高, 内存大, 这个值可以适当调高, 但不能从根本上解决深度分页的问题, 就引入了ES提供的scroll API
SCROLL API
Scroll api的使用包括初始化和遍历两个阶段:
1 初始化阶段
1 | POST /twitter/tweet/_search?scroll=1m |
返回值中会有_scroll_id字段, 这个字段需要保存下来在数据获取阶段使用
2 数据获取
1 | POST /_search/scroll |
scroll缓存时间是每次获取这一批数据的缓存时间, 而且每个请求都会刷新这个时间, 所以不用设置太久, 也不能太长, 维护这个搜索上下文需要开销, 一般设置到能获取两批数据的时间. 源文档:
1 | The scroll parameter (passed to the search request and to every scroll request) tells Elasticsearch how long it should keep the search context alive. Its value (e.g. 1m, see Time unitsedit) does not need to be long enough to process all data — it just needs to be long enough to process the previous batch of results. Each scroll request (with the scroll parameter) sets a new expiry time. |
这种方式的缺点就是不能随机访问每页, 只能一次获取下一批
1 | import json |
数据库中的深度分页问题
这里指的非分布式数据库
常用分页解决方式:
1 | select * from data order by date desc offset 100 limit 10 |
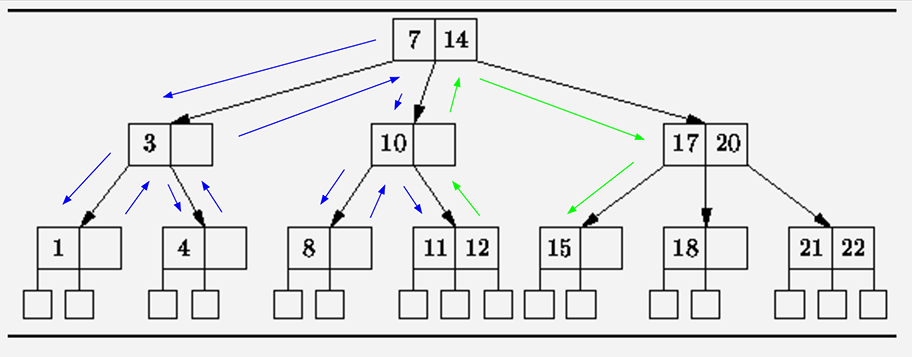
这种方式在较大数据集合上会花费很长时间, 例如page:1000000 size:10, 这种工作方式会扫描page * size条数据, 从BTree的最左侧叶子节点扫描到最右侧叶子节点, 时间复杂度O(n)
(图片来自网络, 如有侵权请联系删除)
解决方法: 记下当前记录结果, 利用索引定位
1 | SELECT * WHERE a > query_point.a ORDER BY a LIMIT=10 OFFSET 9; |
执行过程如下图:
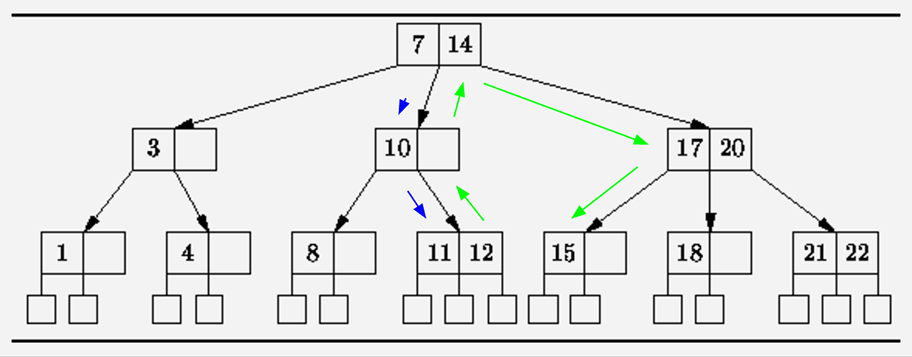
时间复杂度: O(log(page * size) + size)